We previously looked at the background to getting XML into Kafka, and potentially how [not] to do it. Now let’s look at the proper way to build a streaming ingestion pipeline for XML into Kafka, using Kafka Connect.
If you’re unfamiliar with Kafka Connect, check out this quick intro to Kafka Connect here. Kafka Connect’s excellent plugable architecture means that we can pair any source connector to read XML from wherever we have it (for example, a flat file, or a MQ, or anywhere else), with a Single Message Transform to transform the XML into a payload with a schema, and finally a converter to serialise the data in a form that we would like to use such as Avro or Protobuf.
👀 Show me 🕵️♂️ #
| You can try out all this code by spinning up this Docker Compose |
Here’s an example reading XML from a file using the FileStreamSourceConnector (note that this connector plugin is just an example one and not recommended for production use). The output from the source connector is routed through the XML transform that’s configured with the corresponding XSD.
curl -i -X PUT -H "Content-Type:application/json" \
http://localhost:8083/connectors/source-file-note-01/config \
-d '{
"connector.class": "org.apache.kafka.connect.file.FileStreamSourceConnector",
"tasks.max": "1",
"file": "/data/note.xml",
"topic": "note-01",
"transforms": "xml",
"transforms.xml.type": "com.github.jcustenborder.kafka.connect.transform.xml.FromXml$Value",
"transforms.xml.schema.path": "file:///data/note.xsd",
"value.converter": "io.confluent.connect.avro.AvroConverter",
"value.converter.schema.registry.url":"http://schema-registry:8081"
}'The source file looks like this:
<note> <to>Tove</to> <from>Jani</from> <heading>Reminder 01</heading> <body>Don't forget me this weekend!</body> </note>
<note> <to>Jani</to> <from>Tove</from> <heading>Reminder 02</heading> <body>Of course I won't!</body> </note>
<note> <to>Tove</to> <from>Jani</from> <heading>Reminder 03</heading> <body>Where are you?</body> </note>With this connector running the XML is ingested from the source file and written to the note-01 topic:
docker exec kafkacat kafkacat \
-b broker:29092 \
-r http://schema-registry:8081 \
-s avro \
-t note-01 \
-C -o beginning -u -q -J | jq -c '.'{"topic":"note-01","partition":0,"offset":0,"tstype":"create","ts":1601649227632,"broker":1,"key":null,"payload":{"Note":{"to":"Tove","from":"Jani","heading":"Reminder 01","body":"Don't forget me this weekend!"}}}
{"topic":"note-01","partition":0,"offset":1,"tstype":"create","ts":1601649227633,"broker":1,"key":null,"payload":{"Note":{"to":"Jani","from":"Tove","heading":"Reminder 02","body":"Of course I won't!"}}}
{"topic":"note-01","partition":0,"offset":2,"tstype":"create","ts":1601649227633,"broker":1,"key":null,"payload":{"Note":{"to":"Tove","from":"Jani","heading":"Reminder 03","body":"Where are you?"}}}We’re using Avro to serialise the data here (per value.converter, usually set as a global value in the Kafka Connect worker but included here for clarity), and the purpose of the XML transformation was that it applied the schema as declared in the XSD to the data. Taking one of the messages from the topic and pretty-printing it, it looks like this:
{
"topic": "note-01",
"partition": 0,
"offset": 0,
"tstype": "create",
"ts": 1601649227632,
"broker": 1,
"key": null,
"payload": {
"Note": {
"to": "Tove",
"from": "Jani",
"heading": "Reminder 01",
"body": "Don't forget me this weekend!"
}
}
}Without this, and if we just ingested the XML into the Kafka topic, it would look like this:
{
"topic": "note-03",
"partition": 0,
"offset": 0,
"tstype": "create",
"ts": 1601649524495,
"broker": 1,
"key": null,
"payload": "<note> <to>Tove</to> <from>Jani</from> <heading>Reminder 01</heading> <body>Don't forget me this weekend!</body> </note>"
}The difference is a payload with a schema that’s ready to be processed by another application, Kafka Connect, or ksqlDB - and a Kafka message that’s a lump of raw XML still.
Notes on kafka-connect-transform-xml #
I’ve had a a few challenges getting the SMT to work, in particular with certain schemas. Some things to watch out for:
-
You need to have a clear understanding of two things about how Kafka Connect works:
-
The source connector will pass a message that it’s read to the Transformation. At this point so far as the XML SMT is concerned it needs to be a complete XML payload. Therefore, for example, if you are using the FileStreamSourceConnector you’ll need to ensure that full XML document is on a single line, since the source connector treats line breaks as message separators, and so the SMT would get a fragment of XML
-
The SMT will process the whole of the value part of the message. If you have XML as a field within it (for example, reading from a database using the JDBC Source connector, and one field in the table is XML) you’ll need to use the
ExtractFieldtransformation in addition (and first) to the XML transform.
-
To troubleshoot the connector check the Kafka Connect worker log in which you’ll usually see an error explaining the problem. Sometimes you might need to dig deeper and for that there are a couple of useful loggers within the worker that you can bump up to see more of what’s going on:
curl -s -X PUT http://localhost:8083/admin/loggers/org.apache.kafka.connect.runtime.TransformationChain -H "Content-Type:application/json" -d '{"level": "TRACE"}' | jq '.'
curl -s -X PUT http://localhost:8083/admin/loggers/com.github.jcustenborder.kafka.connect -H "Content-Type:application/json" -d '{"level": "TRACE"}' | jq '.'With these set you’ll now capture the details of where Kafka Connect passes the payload to the transformation, which is very useful for sense-checking if the SMT has the correct data with which to work:
TRACE [source-file-note-02|task-0] Applying transformation
com.github.jcustenborder.kafka.connect.transform.xml.FromXml$Value to
SourceRecord{sourcePartition={filename=/data/note.xml}, sourceOffset={position=443}}
ConnectRecord{topic='note-02', kafkaPartition=null, key=null, keySchema=null, value=<note>
<to>Jani</to> <from>Tove</from> <heading>Reminder 04</heading> <body>I forgot 🤷♂️
</body> </note>, valueSchema=Schema{STRING}, timestamp=1601649677317,
headers=ConnectHeaders(headers=)}
(org.apache.kafka.connect.runtime.TransformationChain:47)You also get to see how the SMT itself is handling the data:
TRACE [source-file-note-02|task-0] process() - input.value() has as schema. schema = Schema{STRING} (com.github.jcustenborder.kafka.connect.utils.transformation.BaseKeyValueTransformation:140)
TRACE [source-file-note-02|task-0] toString() - field = 'to' value = 'Jani' (com.github.jcustenborder.kafka.connect.xml.ConnectableHelper:87)
TRACE [source-file-note-02|task-0] toString() - field = 'from' value = 'Tove' (com.github.jcustenborder.kafka.connect.xml.ConnectableHelper:87)
TRACE [source-file-note-02|task-0] toString() - field = 'heading' value = 'Reminder 04' (com.github.jcustenborder.kafka.connect.xml.ConnectableHelper:87)
TRACE [source-file-note-02|task-0] toString() - field = 'body' value = 'I forgot 🤷♂️' (com.github.jcustenborder.kafka.connect.xml.ConnectableHelper:87)Building something useful: Streaming XML messages from IBM MQ into Kafka into MongoDB #
Let’s imagine we have XML data on a queue in IBM MQ, and we want to ingest it into Kafka to then use downstream, perhaps in an application or maybe to stream to a NoSQL store like MongoDB.
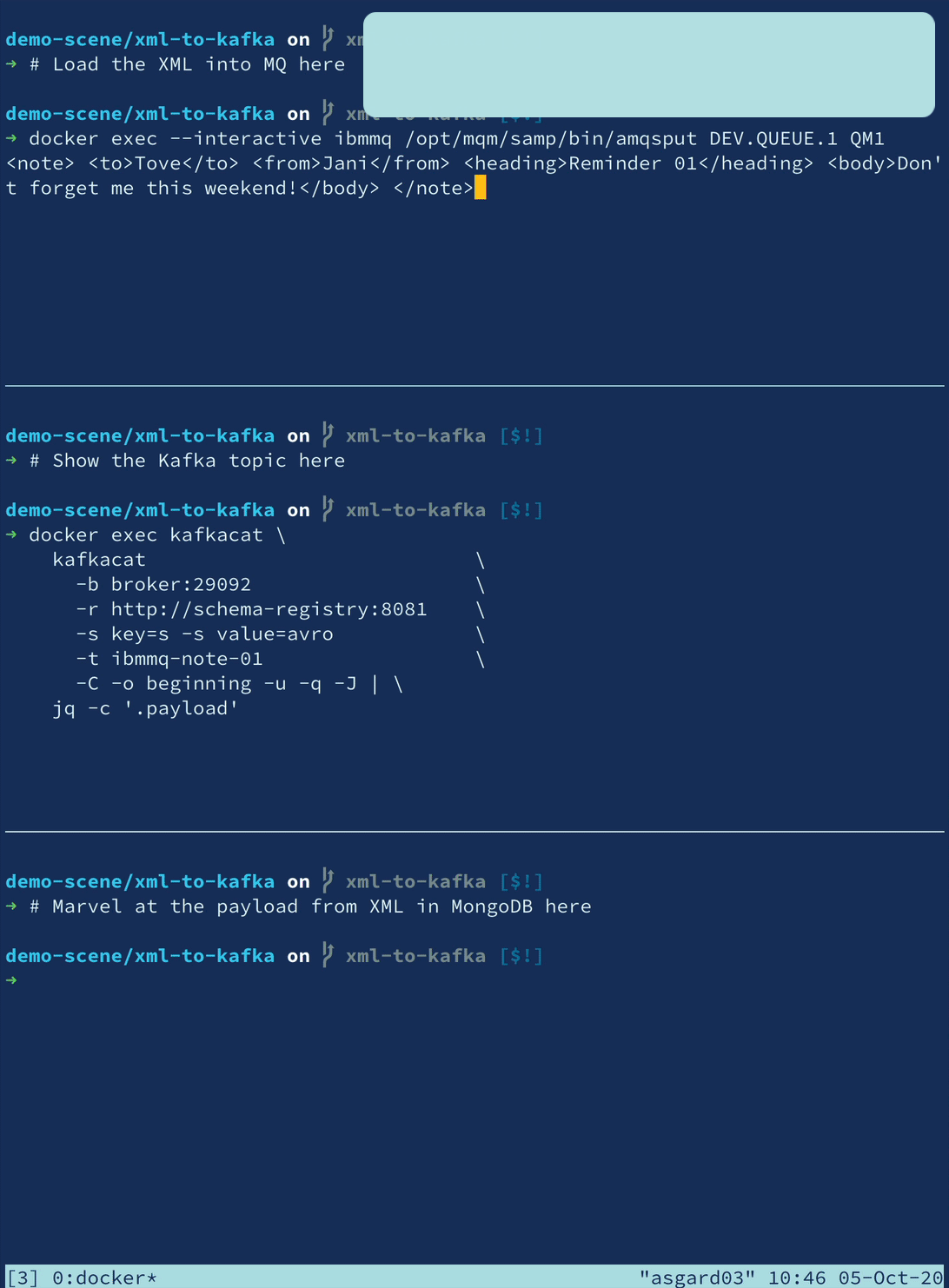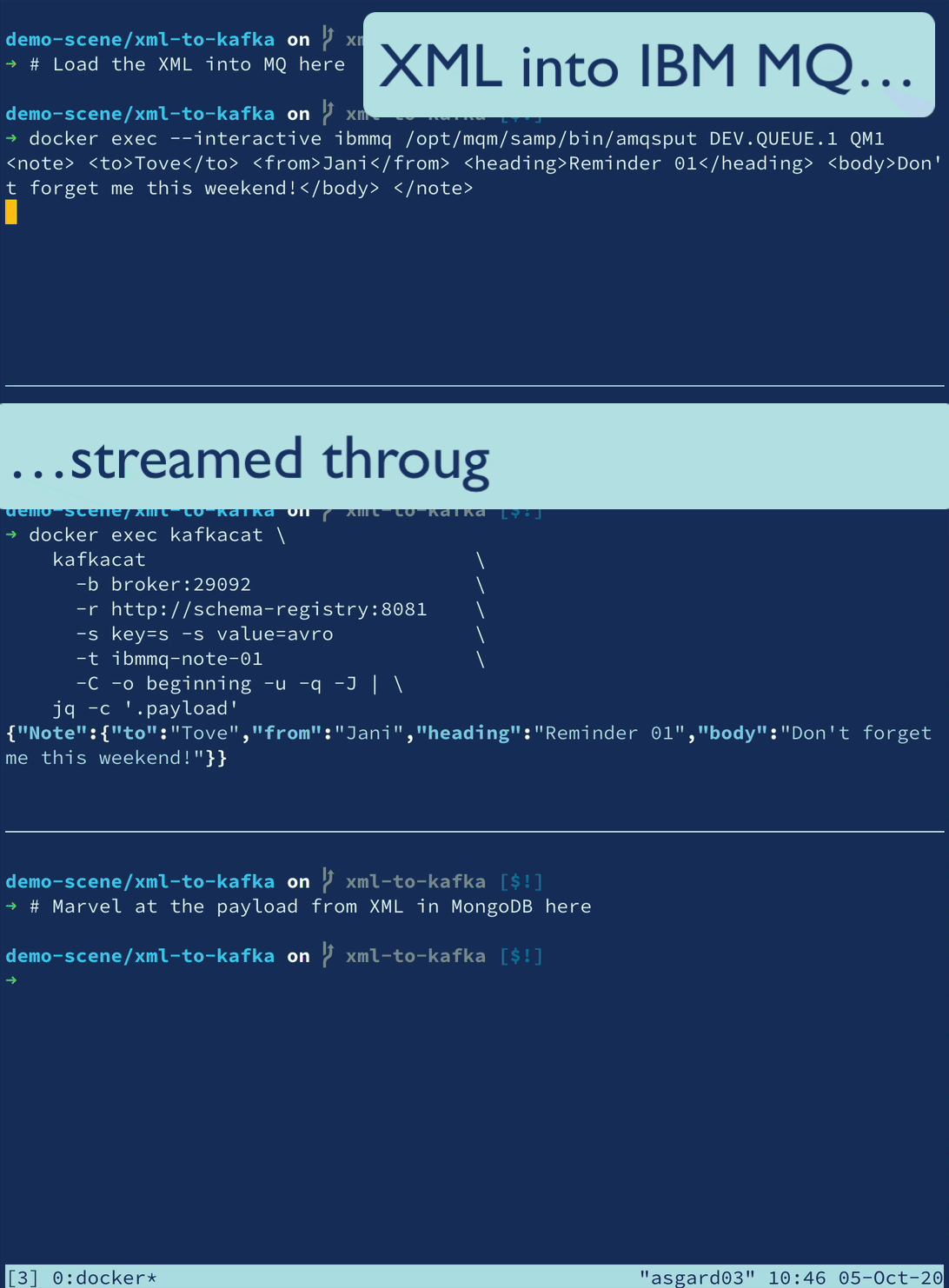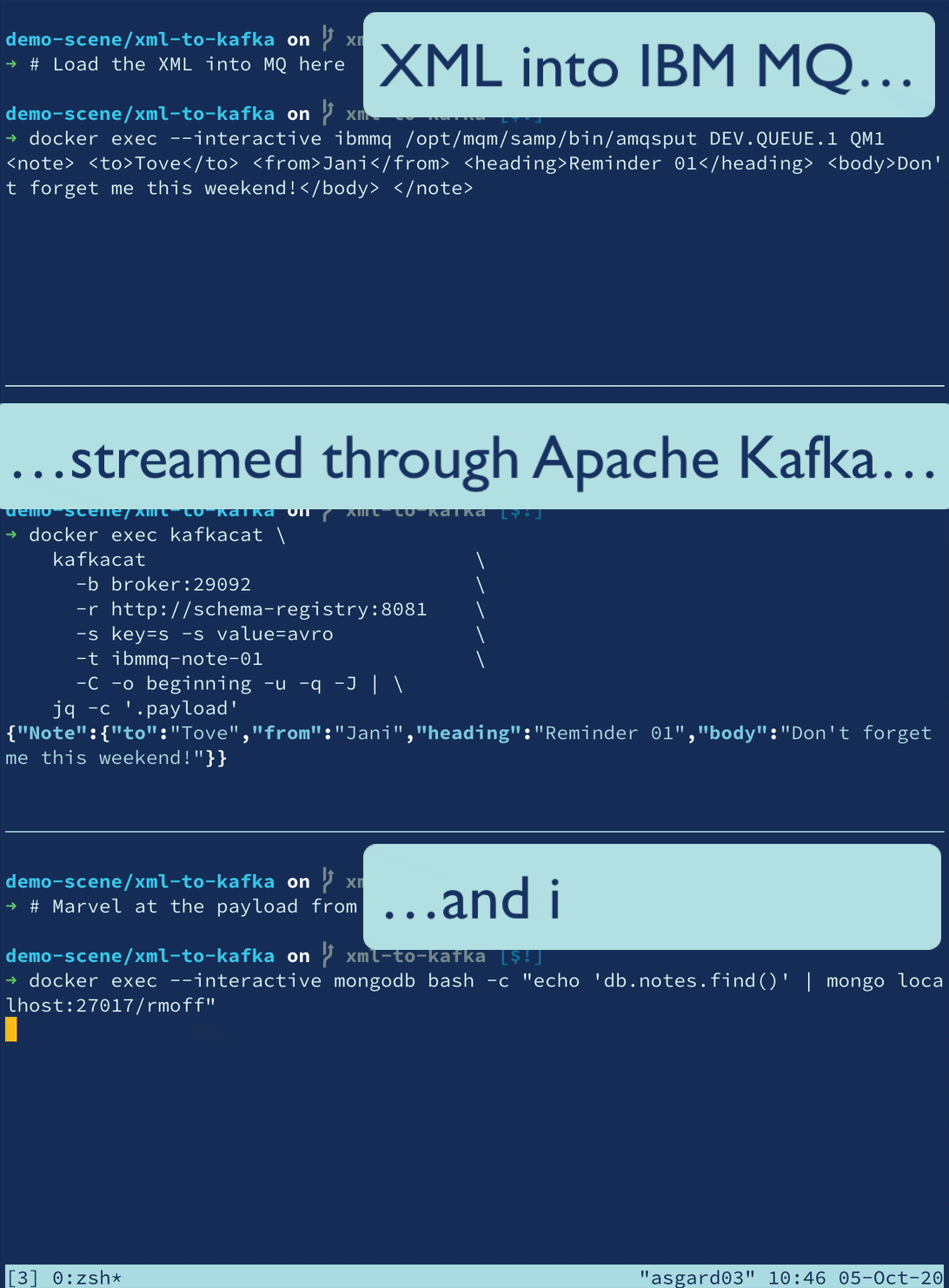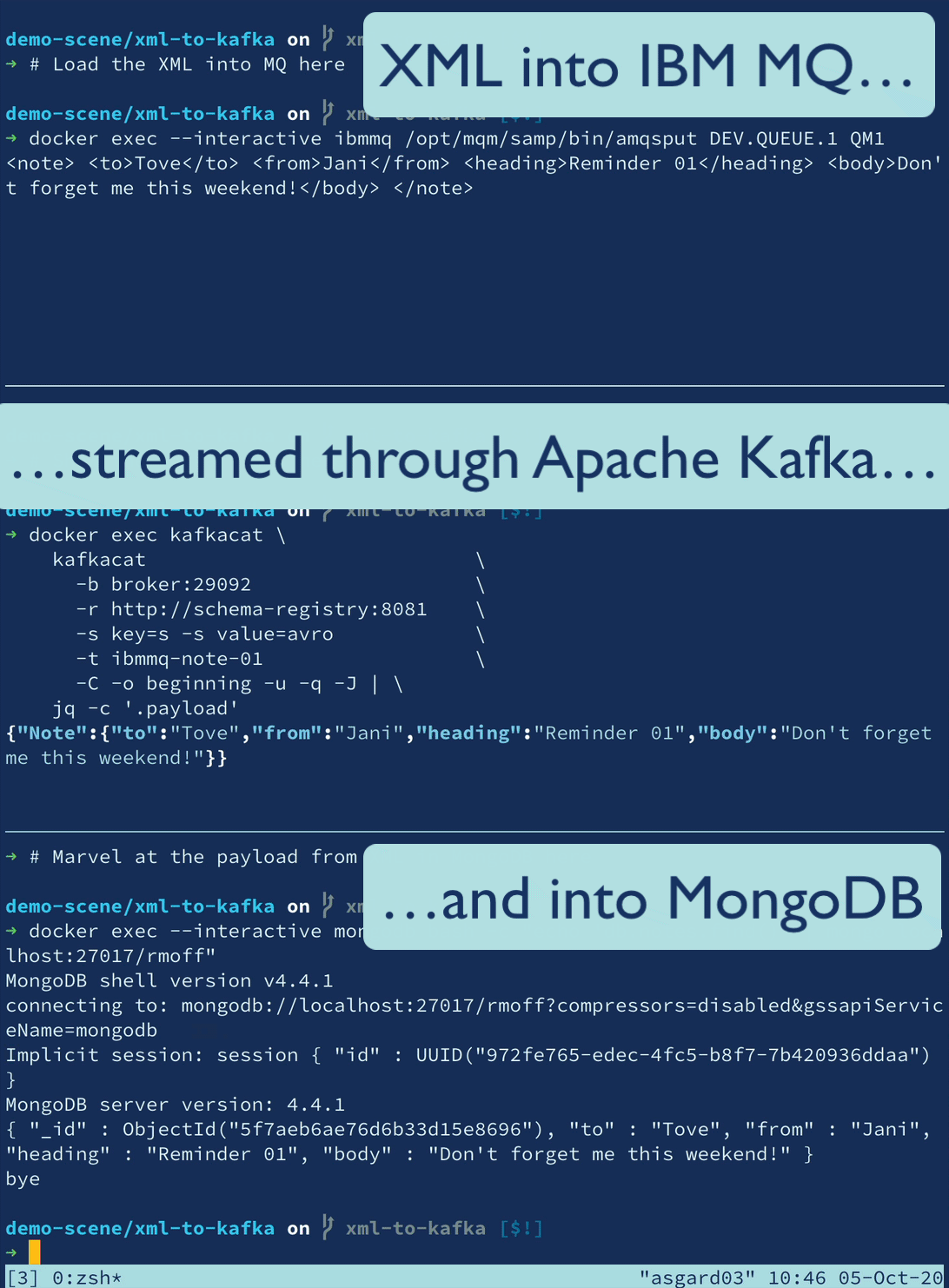
The configuration to ingest from IBM MQ into Kafka using the IbmMQSourceConnector and XML Transformation looks like this (note the use of the ExtractField transformation as discussed above):
curl -i -X PUT -H "Content-Type:application/json" \
http://localhost:8083/connectors/source-ibmmq-note-01/config \
-d '{
"connector.class": "io.confluent.connect.ibm.mq.IbmMQSourceConnector",
"kafka.topic":"ibmmq-note-01",
"mq.hostname":"ibmmq",
"mq.port":"1414",
"mq.queue.manager":"QM1",
"mq.transport.type":"client",
"mq.channel":"DEV.APP.SVRCONN",
"mq.username":"app",
"mq.password":"password123",
"jms.destination.name":"DEV.QUEUE.1",
"jms.destination.type":"queue",
"confluent.license":"",
"confluent.topic.bootstrap.servers":"broker:29092",
"confluent.topic.replication.factor":"1",
"transforms": "extractPayload,xml",
"transforms.extractPayload.type": "org.apache.kafka.connect.transforms.ExtractField$Value",
"transforms.extractPayload.field": "text",
"transforms.xml.type": "com.github.jcustenborder.kafka.connect.transform.xml.FromXml$Value",
"transforms.xml.schema.path": "file:///data/note.xsd",
"value.converter": "io.confluent.connect.avro.AvroConverter",
"value.converter.schema.registry.url":"http://schema-registry:8081"
}'For more details on this see this article.
Is this my best option for getting data into Kafka? #
I reckon it is. The plug 'n play nature of the Kafka Connect components means that you can happily pair up your connector for the source (be it IBM MQ, JMS, Oracle, or anywhere else you have you data) with the XML transformation, and then serialise the resulting data how you choose (Avro/Protobuf/JSON Schema recommended) using the appropriate converter.
The only downside to the XML transform other than a few glitches is that it requires an XSD, rather than being able to infer and work with XPath in the way the Kafka Connect FilePulse connector does.
The other two options are either a bit of a hack, or the Kafka Connect FilePulse connector. The latter is good but constrained to flat-file input only.
