I started my dbt journey by poking and pulling at the pre-built jaffle_shop demo running with DuckDB as its data store. Now I want to see if I can put it to use myself to wrangle the session feedback data that came in from Current 2022. I’ve analysed this already, but it struck me that a particular part of it would benefit from some tidying up - and be a good excuse to see what it’s like using dbt to do so.
Set up #
I’m going to use DuckDB as my datastore because it’s local and all I need at this point. Because of that, I’ll crib salient sections from the jaffle_shop_duckdb demo, as well as make use of the dbt getting started docs.
# Create a project folder
mkdir current-dbt
# Copy the requirements from jaffle_shop_duckdb
cp ../jaffle_shop_duckdb/requirements.txt .
# Download deps and init the environment
python3 -m venv venv
source venv/bin/activate
python3 -m pip install --upgrade pip
python3 -m pip install -r requirements.txt
source venv/bin/activateCreate a ✨sparkly new dbt project✨ with dbt init:
$ dbt init
16:40:45 Running with dbt=1.1.1
16:40:45 Creating dbt configuration folder at /Users/rmoff/.dbt
Enter a name for your project (letters, digits, underscore): current_dbt
Which database would you like to use?
[1] postgres
[2] duckdb
(Don't see the one you want? https://docs.getdbt.com/docs/available-adapters)
Enter a number: 2
16:41:03 No sample profile found for duckdb.
16:41:03
Your new dbt project "current_dbt" was created!
For more information on how to configure the profiles.yml file,
please consult the dbt documentation here:
https://docs.getdbt.com/docs/configure-your-profile
One more thing:
Need help? Don't hesitate to reach out to us via GitHub issues or on Slack:
https://community.getdbt.com/
Happy modeling!From this I get a dbt project structure on disk:
$ ls -lR current_dbt
total 16
-rw-r--r-- 1 rmoff staff 571 20 Oct 17:29 README.md
drwxr-xr-x 3 rmoff staff 96 20 Oct 17:31 analyses
-rw-r--r-- 1 rmoff staff 1337 20 Oct 17:40 dbt_project.yml
drwxr-xr-x 3 rmoff staff 96 20 Oct 17:31 macros
drwxr-xr-x 3 rmoff staff 96 20 Oct 17:31 models
drwxr-xr-x 3 rmoff staff 96 20 Oct 17:31 seeds
drwxr-xr-x 3 rmoff staff 96 20 Oct 17:31 snapshots
drwxr-xr-x 3 rmoff staff 96 20 Oct 17:31 tests
current_dbt/analyses:
total 0
current_dbt/macros:
total 0
current_dbt/models:
total 0
drwxr-xr-x 5 rmoff staff 160 20 Oct 17:31 example
current_dbt/models/example:
total 24
-rw-r--r-- 1 rmoff staff 475 20 Oct 17:29 my_first_dbt_model.sql
-rw-r--r-- 1 rmoff staff 115 20 Oct 17:29 my_second_dbt_model.sql
-rw-r--r-- 1 rmoff staff 437 20 Oct 17:29 schema.yml
current_dbt/seeds:
total 0
current_dbt/snapshots:
total 0
current_dbt/tests:
total 0To this I’m going to add the profiles.yml from the jaffle_shop_duckdb demo and update it for my project.
current_dbt:
target: dev
outputs:
dev:
type: duckdb
path: 'current_dbt.duckdb'
threads: 1So now my root dbt project folder looks like this:
-rw-r--r-- 1 rmoff staff 571B 20 Oct 17:29 README.md
drwxr-xr-x 3 rmoff staff 96B 20 Oct 17:31 analyses
-rw-r--r-- 1 rmoff staff 1.3K 20 Oct 17:40 dbt_project.yml
drwxr-xr-x 3 rmoff staff 96B 20 Oct 17:31 macros
drwxr-xr-x 3 rmoff staff 96B 20 Oct 17:31 models
-rw-r--r-- 1 rmoff staff 118B 21 Oct 09:50 profiles.yml
drwxr-xr-x 5 rmoff staff 160B 21 Oct 10:00 seeds
drwxr-xr-x 3 rmoff staff 96B 20 Oct 17:31 snapshots
drwxr-xr-x 3 rmoff staff 96B 20 Oct 17:31 testsSource Data #
The source data is two files:
-
Session ratings - feedback left by attendees
-
Session scans - number of attendees per session by badge scan count
Both are CSV exports, which I’ve placed in the current_dbt/seeds folder.
To start with I’m simply going to see if I can use dbt seed to load these into DuckDB.
$ dbt seed
09:03:19 Running with dbt=1.1.1
09:03:19 Partial parse save file not found. Starting full parse.
09:03:20 Found 2 models, 4 tests, 0 snapshots, 0 analyses, 167 macros, 0 operations, 2 seed files, 0 sources, 0 exposures, 0 metrics
09:03:20
09:03:20 Concurrency: 1 threads (target='dev')
09:03:20
09:03:20 1 of 2 START seed file main.rating_detail ...................................... [RUN]
09:03:21 1 of 2 OK loaded seed file main.rating_detail .................................. [INSERT 2416 in 0.61s]
09:03:21 2 of 2 START seed file main.session_scans ...................................... [RUN]
09:03:21 2 of 2 OK loaded seed file main.session_scans .................................. [INSERT 163 in 0.10s]
09:03:21
09:03:21 Finished running 2 seeds in 0.86s.
09:03:21
09:03:21 Completed successfully
09:03:21
09:03:21 Done. PASS=2 WARN=0 ERROR=0 SKIP=0 TOTAL=2Holy smokes! There’s now a DuckDB file created, and within it two tables holding data! And all I did was drop two CSV files into a folder and run dbt seed.
$ ls -l *.duckdb
-rw-r--r-- 1 rmoff staff 2109440 21 Oct 10:03 current_dbt.duckdbcurrent_dbt.duckdb> \dt
+---------------+
| name |
+---------------+
| rating_detail |
| session_scans |
+---------------+
Time: 0.018s
current_dbt.duckdb> describe session_scans;
+-----+--------------------------------------------------------+---------+---------+------------+-------+
| cid | name | type | notnull | dflt_value | pk |
+-----+--------------------------------------------------------+---------+---------+------------+-------+
| 0 | Session Code | VARCHAR | False | <null> | False |
| 1 | Day | VARCHAR | False | <null> | False |
| 2 | Start | VARCHAR | False | <null> | False |
| 3 | End | VARCHAR | False | <null> | False |
| 4 | Speakers | VARCHAR | False | <null> | False |
| 5 | Name | VARCHAR | False | <null> | False |
| 6 | Scans | VARCHAR | False | <null> | False |
| 7 | Location | VARCHAR | False | <null> | False |
| 8 | Average Sesion Rating | DOUBLE | False | <null> | False |
| 9 | # Survey Responses | INTEGER | False | <null> | False |
| 10 | Please rate your overall experience with this session. | DOUBLE | False | <null> | False |
| 11 | Please rate the quality of the content. | DOUBLE | False | <null> | False |
| 12 | Please rate your satisfaction with the presenter. | DOUBLE | False | <null> | False |
[…]
+-----+--------------------------------------------------------+---------+---------+------------+-------+
Time: 0.011s
current_dbt.duckdb> describe rating_detail;
+-----+---------------+---------+---------+------------+-------+
| cid | name | type | notnull | dflt_value | pk |
+-----+---------------+---------+---------+------------+-------+
| 0 | sessionID | INTEGER | False | <null> | False |
| 1 | title | VARCHAR | False | <null> | False |
| 2 | Start Time | VARCHAR | False | <null> | False |
| 3 | Rating Type | VARCHAR | False | <null> | False |
| 4 | Rating Type_2 | VARCHAR | False | <null> | False |
| 5 | rating | INTEGER | False | <null> | False |
| 6 | Comment | VARCHAR | False | <null> | False |
| 7 | User ID | INTEGER | False | <null> | False |
| 8 | First | VARCHAR | False | <null> | False |
| 9 | Last | VARCHAR | False | <null> | False |
| 10 | Email | VARCHAR | False | <null> | False |
| 11 | Sponsor Share | VARCHAR | False | <null> | False |
| 12 | Account Type | VARCHAR | False | <null> | False |
| 13 | Attendee Type | VARCHAR | False | <null> | False |
+-----+---------------+---------+---------+------------+-------+
Time: 0.009s
current_dbt.duckdb>Pretty nice! So let’s think now about what we want to do with this data.
Data Wrangling: The Spec #
There are several things I want to do with the data:
-
Create a single detail table of all rating comments and scores
-
Create a summary table of both rating and attendance data
-
Remove PII data of those who left ratings
-
Rename fields to remove spaces etc
-
Pivot the "Rating Type" / "rating" values into a set of columns.
In its current form it looks like this:
current_dbt.duckdb> select SessionID, "Rating Type", rating from rating_detail; +-----------+--------------------+--------+ | SessionID | Rating Type | rating | +-----------+--------------------+--------+ | 42 | Overall Experience | 5 | | 42 | Presenter | 5 | | 42 | Content | 4 | | 42 | Overall Experience | 5 | | 42 | Presenter | 5 | | 42 | Content | 5 | +-----------+--------------------+--------+ 6 rows in set Time: 0.009sIn the final table it would be better to pivot these into individual fields like this:
+------------+----------------+------------------+----------------+ | session_id | content_rating | presenter_rating | overall_rating | +------------+----------------+------------------+----------------+ | 42 | <null> | <null> | 5 | | 42 | <null> | 5 | <null> | | 42 | 4 | <null> | <null> | | 42 | <null> | <null> | 5 | | 42 | <null> | 5 | <null> | | 42 | 5 | <null> | <null> | +------------+----------------+------------------+----------------+ 6 rows in set Time: 0.009sWith the data structured like this analyses can be more easily run against the data.
-
Unify the identifier used for sessions - at the moment the two sets of data use
Session CodeandsessionIDwhich don’t relate and are sometimesnull. The only common link is the title of the session itself.current_dbt.duckdb> select r.sessionID, s."Session Code", r.title from rating_detail r inner join session_scans s on r.title=s.name using sample 5; +-----------+--------------+-----------------------------------------------------------------------------------------------+ | sessionID | Session Code | title | +-----------+--------------+-----------------------------------------------------------------------------------------------+ | 140 | 50650015-1 | A Crash Course in Designing Messaging APIs | | 33 | 50650015-2 | You're Spiky and We Know It - Twilio's journey on Handling Data Spikes for Real-Time Alerting | | 141 | 50650011-7 | Bootiful Kafka: Get the Message! | | 139 | <null> | KEYNOTE: Apache Kafka: Past, Present, & Future | | 104 | 50650048-4 | Knock Knock, Who's There? Identifying Kafka Clients in a Multi-tenant Environment | +-----------+--------------+-----------------------------------------------------------------------------------------------+ 5 rows in set Time: 0.009s -
Create a new field showing if an attendee who left a session rating was there in-person or not. The source data has
Attendee Typefield but this is more granular and exposes more data than we’d like to to the end analystcurrent_dbt.duckdb> select "Attendee type" , count(*) from main_seed_data.rating_detail group by "Attendee Type" order by 1; +--------------------+--------------+ | Attendee Type | count_star() | +--------------------+--------------+ | Employee | 126 | | General | 1334 | | Speaker | 298 | […] | Virtual | 537 | +--------------------+--------------+ 15 rows in set Time: 0.008s -
Exclude session data for mealtimes (whilst this data is important, it’s outside my scope of analysis)
-
Pivot the session track into a single field. Currently the data has a field for each track and a check in the appropriate one. Very spreadsheet-y, not very RDBMS-y:
current_dbt.duckdb> select * from main_seed_data.session_scans using sample 10; + […] -+--------------+------------------+------------------------------+ | […] | Kafka Summit | Modern Data Flow | Operations and Observability | + […] -+--------------+------------------+------------------------------+ | […] | x | <null> | x | | […] | <null> | <null> | <null> | | […] | x | x | <null> | | […] | x | x | <null> | | […] | <null> | <null> | x | | […] | <null> | x | <null> | | […] | <null> | <null> | x | | […] | x | <null> | <null> | | […] | <null> | x | <null> | | […] | <null> | <null> | <null> | + […] -+--------------+------------------+------------------------------+ 10 rows in set Time: 0.025sI’d rather narrow the table into a single
LISTof track(s) for each session, something like:+ […] -+----------------------------------------------------+ | […] | Track | + […] -+----------------------------------------------------+ | […] | ['Kafka Summit','Operations and Observability'] | | […] | ['Kafka Summit'] | | […] | ['Kafka Summit'] | | […] | ['Modern Data Flow'] | + […] -+----------------------------------------------------+
My First Model 👨🎓 #
Staging model #1: Rating Detail (stg_rating) #
Following the pattern of the jaffle shop demo, I’m going to use staging tables to tidy up the raw data to start with.
We’ll check the pattern works first with one table (rating_detail) and then move on to the other.
In starting to write out the SQL I noticed a problem in my naming:
with source as (
select * from {{ ref('rating_detail')}}
)Although the ref here is to the seed data, it made me think about the database object names. If my source raw data is going to be loaded into a table called rating_detail then it’s potentially going to get rather confusing. I want to either use a name prefix or perhaps a separate database catalog (schema) for this raw data that I’ve loaded. Checking the docs I found the seed configuration including an option to set the schema.
So I’ve added to my dbt_project.yml the following:
seeds:
+schema: seed_dataI could drop the existing tables directly (just to keep things tidy), but in all honesty it’s quicker just to remove the database and let DuckDB create a new one when we re-run the seed command.
$ rm current_dbt.duckdb
$ dbt seed
13:26:03 Running with dbt=1.1.1
13:26:03 Unable to do partial parsing because a project config has changed
13:26:03 Found 2 models, 4 tests, 0 snapshots, 0 analyses, 167 macros, 0 operations, 2 seed files, 0 sources, 0 exposures, 0 metrics
13:26:03
13:26:04 Concurrency: 1 threads (target='dev')
13:26:04
13:26:04 1 of 2 START seed file main_seed_data.rating_detail ............................ [RUN]
13:26:04 1 of 2 OK loaded seed file main_seed_data.rating_detail ........................ [INSERT 2416 in 0.54s]
13:26:04 2 of 2 START seed file main_seed_data.session_scans ............................ [RUN]
13:26:04 2 of 2 OK loaded seed file main_seed_data.session_scans ........................ [INSERT 163 in 0.11s]
13:26:04
13:26:04 Finished running 2 seeds in 0.84s.
13:26:04
13:26:04 Completed successfully
13:26:04
13:26:04 Done. PASS=2 WARN=0 ERROR=0 SKIP=0 TOTAL=2Now my seed data is loaded into two tables in their own schema:
$ duckdb current_dbt.duckdb -c "select table_schema, table_name, table_type from information_schema.tables;"
┌────────────────┬───────────────┬────────────┐
│ table_schema │ table_name │ table_type │
├────────────────┼───────────────┼────────────┤
│ main_seed_data │ rating_detail │ BASE TABLE │
│ main_seed_data │ session_scans │ BASE TABLE │
└────────────────┴───────────────┴────────────┘So back to my staging model. Here’s my first pass at the clean up of rating_detail based on the relevant points of the spec above to implement at this stage.
WITH source_data AS (
-- Spec #4: Rename fields to remove spaces etc
SELECT title AS session_name,
"Rating Type" AS rating_type,
rating,
"comment" AS rating_comment,
"Attendee Type" AS attendee_type
-- Spec #7 Create a new field showing if attendee was in-person or not
CASE WHEN "Attendee Type" = 'Virtual' THEN 1 ELSE 0 AS virtual_attendee
-- Spec #3: Remove PII data of those who left ratings
FROM {{ ref('rating_detail') }}
)
SELECT *
FROM source_data
-- Spec #8: Exclude irrelevant sessions
WHERE session_name NOT IN ('Breakfast', 'Lunch', 'Registration')Let’s compile it and see how it goes. Before I do this I’m going to tear off the training wheels and remove the example models - we can do this for ourselves :-)
$ rm -rf models/example$ dbt compile
14:24:11 Running with dbt=1.1.1
14:24:12 [WARNING]: Configuration paths exist in your dbt_project.yml file which do not apply to any resources.
There are 1 unused configuration paths:
- models.current_dbt.example
14:24:12 Found 1 model, 0 tests, 0 snapshots, 0 analyses, 167 macros, 0 operations, 2 seed files, 0 sources, 0 exposures, 0 metrics
14:24:12
14:24:12 Concurrency: 1 threads (target='dev')
14:24:12
14:24:12 Done.A warning which we’ll look at later, but for now it looks like the compile succeeded. Let’s check the output:
$ cat ./target/compiled/current_dbt/models/staging/stg_ratings.sql
WITH source_data AS (
-- Spec #4: Rename fields to remove spaces etc
SELECT title AS session_name,
"Rating Type" AS rating_type,
rating,
"comment" AS rating_comment,
"Attendee Type" AS attendee_type
-- Spec #7 Create a new field showing if attendee was in-person or not
CASE WHEN "Attendee Type" = 'Virtual' THEN 1 ELSE 0 AS virtual_attendee
-- Spec #3: Remove PII data of those who left ratings
FROM "main"."main_seed_data"."rating_detail"
)
SELECT *
FROM source_data
-- Spec #8: Exclude irrelevant sessions
WHERE session_name NOT IN ('Breakfast', 'Lunch', 'Registration')I’m not sure if the qualification of the schema looks right here FROM "main"."main_seed_data"."rating_detail" but let’s worry about that when we need to. Which is right now, because I’m going to try and run this model too. Over in the dbt_project.yml I’ll tell it to create the staging model as a view (and in the process fix the warning above about the unused examples path):
models:
current_dbt:
staging:
+materialized: viewWith that set, let’s try running it. If all goes well, I’ll get a view created in DuckDB.
$ dbt run
14:27:41 Running with dbt=1.1.1
14:27:41 Unable to do partial parsing because a project config has changed
14:27:42 Found 1 model, 0 tests, 0 snapshots, 0 analyses, 167 macros, 0 operations, 2 seed files, 0 sources, 0 exposures, 0 metrics
14:27:42
14:27:42 Concurrency: 1 threads (target='dev')
14:27:42
14:27:42 1 of 1 START view model main.stg_ratings ....................................... [RUN]
14:27:42 1 of 1 ERROR creating view model main.stg_ratings .............................. [ERROR in 0.05s]
14:27:42
14:27:42 Finished running 1 view model in 0.24s.
14:27:42
14:27:42 Completed with 1 error and 0 warnings:
14:27:42
14:27:42 Runtime Error in model stg_ratings (models/staging/stg_ratings.sql)
14:27:42 Parser Error: syntax error at or near "CASE"
14:27:42 LINE 12: CASE WHEN "Attendee Type" = 'Virtual' THEN 1 ELSE 0 AS virtual_attendee
14:27:42 -- Spec #3: Remove PII data of those who left ratings
14:27:42 FROM "main"."main_seed_data"."rating_detail"
14:27:42 )
14:27:42
14:27:42 SELECT *
14:27:42 FROM source_data
14:27:42 -- Spec #8: Exclude irrelevant sessions
14:27:42 WHERE session_name NOT IN ('Breakfast', 'Lunch', 'Registration')
14:27:42 );
14:27:42 ...
14:27:42 ^
14:27:42
14:27:42 Done. PASS=0 WARN=0 ERROR=1 SKIP=0 TOTAL=1Well, all didn’t go well.
Runtime Error in model stg_ratings (models/staging/stg_ratings.sql)
Parser Error: syntax error at or near "CASE"Hmmm. So it turns out that the compile will compile but not parse the SQL for validity. Rookie SQL mistake right here:
"Attendee Type" AS attendee_type
CASE WHEN "Attendee Type" = 'Virtual' THEN 1 ELSE 0 AS virtual_attendeeCan you see it? Or rather, not see it?
How about now?
-- 👇️👀
"Attendee Type" AS attendee_type,
CASE WHEN "Attendee Type" = 'Virtual' THEN 1 ELSE 0 AS virtual_attendeeWith the errant comma put in its place after attendee_type, and then subsequently the missing END that the eagle-eyed amongst you will have spotted inserted in the CASE statement, things look better:
"Attendee Type" AS attendee_type,
CASE WHEN "Attendee Type" = 'Virtual' THEN 1 ELSE 0 END AS virtual_attendeeand as if by magic…
$ dbt run
14:55:57 Running with dbt=1.1.1
14:55:57 Found 1 model, 0 tests, 0 snapshots, 0 analyses, 167 macros, 0 operations, 2 seed files, 0 sources, 0 exposures, 0 metrics
14:55:57
14:55:57 Concurrency: 1 threads (target='dev')
14:55:57
14:55:57 1 of 1 START view model main.stg_ratings ....................................... [RUN]
14:55:57 1 of 1 OK created view model main.stg_ratings .................................. [OK in 0.08s]
14:55:57
14:55:57 Finished running 1 view model in 0.24s.
14:55:57
14:55:57 Completed successfully
14:55:57
14:55:57 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1(turns out the schema qualification I was worrying about worked just fine)
Check it out!
$ duckdb current_dbt.duckdb -c "select table_schema, table_name, table_type from information_schema.tables;"
┌────────────────┬───────────────┬────────────┐
│ table_schema │ table_name │ table_type │
├────────────────┼───────────────┼────────────┤
│ main_seed_data │ session_scans │ BASE TABLE │
│ main_seed_data │ rating_detail │ BASE TABLE │
│ main │ stg_ratings │ VIEW │
└────────────────┴───────────────┴────────────┘
$ duckdb current_dbt.duckdb -c "select * from stg_ratings using sample 5;"
┌────────────────┬────────────────────┬────────┬─────────────────────┬─────────────────┬──────────────────┐
│ session_name │ rating_type │ rating │ rating_comment │ attendee_type │ virtual_attendee │
├────────────────┼────────────────────┼────────┼─────────────────────┼─────────────────┼──────────────────┤
│ Session x │ Content │ 4 │ Need more cheetohs │ Sponsor │ 0 │
│ Session y .. │ Content │ 3 │ │ General │ 0 │
│ Session z │ Presenter │ 4 │ Great hair, ... │ Sponsor │ 0 │
│ Session foo .. │ Overall Experience │ 5 │ │ Virtual │ 1 │
│ Session bar .. │ Presenter │ 5 │ │ General │ 0 │
└────────────────┴────────────────────┴────────┴─────────────────────┴─────────────────┴──────────────────┘(actual footage of me with my lockdown beard 😉 )
The last thing we need to do is #5 in the spec above — pivot the rating types into in individual columns, turning this:
+-----------+-----------+--------+
| SessionID |Rating Type| rating |
+-----------+-----------+--------+
| 42 | Overall | 5 |
| 42 | Presenter | 5 |
| 42 | Content | 4 |
| 42 | Overall | 5 |
| 42 | Presenter | 5 |
| 42 | Content | 5 |
+-----------+-----------+--------+into this:
+------------+----------------+------------------+----------------+
| session_id | content_rating | presenter_rating | overall_rating |
+------------+----------------+------------------+----------------+
| 42 | <null> | <null> | 5 |
| 42 | <null> | 5 | <null> |
| 42 | 4 | <null> | <null> |
| 42 | <null> | <null> | 5 |
| 42 | <null> | 5 | <null> |
| 42 | 5 | <null> | <null> |
+------------+----------------+------------------+----------------+For this I’m going to try my hand at some Jinja since this feels like a great place for it. To start with, I’ll first get the unique set of values:
current_dbt.duckdb> select distinct rating_type from stg_ratings;
+--------------------+
| rating_type |
+--------------------+
| Overall Experience |
| Presenter |
| Content |
+--------------------+
3 rows in set
Time: 0.010sand build this into a Jinja variable in the model:
{% set rating_types = ['Overall Experience','Presenter', 'Content'] %}and then use this to build several CASE statements:
-- Spec #5: Pivot rating type into individual columns
{% for r in rating_types -%}
CASE WHEN rating_type = '{{ r }}' THEN rating END AS {{ r.lower().replace(' ','_') }}_rating,
CASE WHEN rating_type = '{{ r }}' THEN "comment" END AS {{ r.lower().replace(' ','_') }}_comment,
{% endfor -%}Note the use of .lower() and .replace to force the name to lowercase and replace spaces with underscores. Otherwise you end up with column names like "Overall Experience_comment" instead of overall_experience_comment.
Here’s the finished model:
{% set rating_types = ['Overall Experience','Presenter', 'Content'] %}
WITH source_data AS (
-- Spec #4: Rename fields to remove spaces etc
SELECT TRIM(title) AS session_name,
-- Spec #5: Pivot rating type into individual columns
{% for r in rating_types -%}
CASE WHEN "Rating Type" = '{{ r }}' THEN rating END AS {{ r.lower().replace(' ','_') }}_rating,
CASE WHEN "Rating Type" = '{{ r }}' THEN "comment" END AS {{ r.lower().replace(' ','_') }}_comment,
{% endfor -%}
-- Spec #7 Create a new field showing if attendee was in-person or not
CASE WHEN "Attendee Type" = 'Virtual' THEN 1 ELSE 0 END AS virtual_attendee
-- Spec #3: Remove PII data of those who left ratings
FROM {{ ref('rating_detail') }}
)
SELECT *
FROM source_data
-- Spec #8: Exclude irrelevant sessions
WHERE session_name NOT IN ('Breakfast', 'Lunch', 'Registration')Which creates a table that looks like this:
+-----+----------------------------+---------+
| cid | name | type |
+-----+----------------------------+---------+
| 0 | session_name | VARCHAR |
| 1 | overall_experience_rating | INTEGER |
| 2 | overall_experience_comment | VARCHAR |
| 3 | presenter_rating | INTEGER |
| 4 | presenter_comment | VARCHAR |
| 5 | content_rating | INTEGER |
| 6 | content_comment | VARCHAR |
| 7 | attendee_type | VARCHAR |
| 8 | virtual_attendee | INTEGER |
+-----+----------------------------+---------+Staging model #2: Session Scans (stg_scans) #
Let’s build the other staging model now. The only point of interest here is combining the numerous fields that represent all the tracks and have a value in them if the associated session was in that track.
The SQL pattern I want to replicate is this:
-
In a CTE (Common Table Expression), for each field, if it’s not
NULLthen return a single-entryLISTwith the name (not value) of the field -
Select from the CTE and use
LIST_CONCATto condense all theLISTfields
If it’s easier to visualise it then here’s a test dataset that mimics the source:
+--------+--------+
| A | B |
+--------+--------+
| <null> | X |
| X | <null> |
| X | X |
+--------+--------+and here’s the resulting transformation:
WITH X AS (SELECT A, B,
CASE WHEN A='X' THEN ['A'] END AS F0,
CASE WHEN B='X' THEN ['B'] END AS F1
FROM FOO)
SELECT LIST_CONCAT(F0, F1) AS COMBINED_FLAGS FROM X
+----------------+
| COMBINED_FLAGS |
+----------------+
| ['B'] |
| ['A'] |
| ['A', 'B'] |
+----------------+Here’s my stg_scans model using this approach. Note also the use of loop.index to create the required number of field aliases that can then be referenced in the subsequent SELECT.
{% set tracks = ['Architectures You've Always Wondered About','Case Studies','Data Development Life Cycle','Developing Real-Time Applications','Event Streaming in Academia and Beyond','Fun and Geeky','Kafka Summit','Modern Data Flow','Operations and Observability','Panel','People & Culture','Real Time Analytics','Sponsored Session','Streaming Technologies'] %}
WITH source_data AS (
-- Spec #4: Rename fields to remove spaces etc
SELECT NAME AS session_name,
Speakers AS speakers,
scans AS scans,
"# Survey Responses" AS rating_ct,
-- Spec #9 Combine all track fields into a single summary
{% for t in tracks -%}
CASE WHEN t IS NOT NULL THEN ['t'] END
AS F{{ loop.index }},
{% endfor -%}
FROM {{ ref('session_scans') }}
)
SELECT session_name,
speakers,
scans,
rating_ct,
LIST_CONCAT(
{% for t in tracks -%}
F{{ loop.index }},
{% endfor -%}
) AS track
FROM source_dataIs it just me, or are you deeply suspicious when your code runs the first time of trying without error?
$ dbt run --select stg_scans
16:17:19 Running with dbt=1.1.1
16:17:19 Found 2 models, 0 tests, 0 snapshots, 0 analyses, 167 macros, 0 operations, 2 seed files, 0 sources, 0 exposures, 0 metrics
16:17:19
16:17:19 Concurrency: 1 threads (target='dev')
16:17:19
16:17:19 1 of 1 START view model main.stg_scans ......................................... [RUN]
16:17:19 1 of 1 OK created view model main.stg_scans .................................... [OK in 0.08s]
16:17:19
16:17:19 Finished running 1 view model in 0.20s.
16:17:20
16:17:20 Completed successfully
16:17:20
16:17:20 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1and then you go to check the resulting view… and it’s exactly that same as the one you just built with a different name?
current_dbt.duckdb> describe stg_scans;
+-----+------------------+---------+---------+------------+-------+
| cid | name | type | notnull | dflt_value | pk |
+-----+------------------+---------+---------+------------+-------+
| 0 | session_name | VARCHAR | False | <null> | False |
| 1 | rating_type | VARCHAR | False | <null> | False |
| 2 | rating | INTEGER | False | <null> | False |
| 3 | rating_comment | VARCHAR | False | <null> | False |
| 4 | attendee_type | VARCHAR | False | <null> | False |
| 5 | virtual_attendee | INTEGER | False | <null> | False |
+-----+------------------+---------+---------+------------+-------+
Time: 0.009s…because you copied the source and didn’t save it so dbt was just running exactly the same as before but with a different name.
Let’s save our masterpiece and try actually running that instead:
$ dbt run --select stg_scans
16:22:33 Running with dbt=1.1.1
16:22:33 Encountered an error:
Compilation Error in model stg_scans (models/staging/stg_scans.sql)
expected token ',', got 've'
line 1
{% set tracks = ['Architectures You've Always Wondered About',
[…]Phew - an error. I mean, that’s a shame, but at least it’s running the code we wanted it to :)
The error was an unescaped quote, so let’s fix that and try again.
16:23:35 Completed with 1 error and 0 warnings:
16:23:35
16:23:35 Runtime Error in model stg_scans (models/staging/stg_scans.sql)
16:23:35 Parser Error: syntax error at or near ")"
16:23:35 LINE 62: ) AS track
16:23:35 ^Not sure a clear error this time. Let’s check out the compiled SQL to see if our Jinja magic is working.
$ cat ./target/compiled/current_dbt/models/staging/stg_scans.sql
WITH source_data AS (
-- Spec #4: Rename fields to remove spaces etc
SELECT NAME AS session_name,
Speakers AS speakers,
scans AS scans,
"# Survey Responses" AS rating_ct,
-- Spec #9 Combine all track fields into a single summary
CASE WHEN t IS NOT NULL THEN ['t'] END
AS F1,
CASE WHEN t IS NOT NULL THEN ['t'] END
AS F2,
[…]
FROM "main"."main_seed_data"."session_scans"
)
SELECT session_name,
speakers,
scans,
rating_ct,
LIST_CONCAT(
F1,
F2,
[…]
) AS track
FROM source_dataSo some of it’s working. The incrementing field name (F1, F2, etc), and the list iteration. However, the t literal shouldn’t be there - and that’s because I didn’t enclose it in the magic double curly braces {{ fun happens here }}.
CASE WHEN t IS NOT NULL THEN ['t'] ENDshould be
CASE WHEN {{ t }} IS NOT NULL THEN ['{{ t }}'] ENDLet’s compile that and see:
$ cat ./target/compiled/current_dbt/models/staging/stg_scans.sql
WITH source_data AS (
-- Spec #4: Rename fields to remove spaces etc
SELECT NAME AS session_name,
Speakers AS speakers,
scans AS scans,
"# Survey Responses" AS rating_ct,
-- Spec #9 Combine all track fields into a single summary
CASE WHEN Architectures You've Always Wondered About IS NOT NULL THEN ['Architectures You've Always Wondered About'] END
AS F1,
CASE WHEN Case Studies IS NOT NULL THEN ['Case Studies'] END
AS F2,
CASE WHEN Data Development Life Cycle IS NOT NULL THEN ['Data Development Life Cycle'] END
AS F3,
[…]We’re making progress! The field name needs double-quoting, and we need to work out how to escape the ' in some of the values. The former is simple enough, and the latter is solved with a quick visit to the dbt docs and their excellent search which hits escape_single_quotes straight away…
…which turns out to not be so simple because the dbt version I’m using (1.1.1) needs to be >=1.2 to use the function. For now I’m going to omit the problematic track and worry about it at a later point if I have chance to figure out upgrading :)
So, having figured out the first Jinja problem (and hacked our way around it by fudging the data), let’s go back to the error that we had before:
Parser Error: syntax error at or near ")"
LINE 60: ) AS trackIf we look at the compiled SQL, we’ll see this:
[…]
SELECT session_name,
speakers,
scans,
rating_ct,
LIST_CONCAT(
F1,
F2,
[…]
F13,
) AS track
FROM source_dataNotice that trailing comma after the final field iteration (F13)? That’s causing the error.
The problem comes from this bit of code:
LIST_CONCAT(
{% for t in tracks -%}
F{{ loop.index }},
{% endfor -%}
) AS trackThe loop includes a field seperator , every iteration which is mostly what we want—except we don’t want it on the final iteration. Let’s see if we can code around that by checking our index in the iteration (loop.index) against the length of the list (tracks|length):
LIST_CONCAT(
{% for t in tracks -%}
-- Literal If the current loop index Literal
-- | Loop index is not the last one THEN | end if
-- | | | | |
-- V\--------------/ \---------------------------------/V \---------/
F{{ loop.index }} {% if loop.index < tracks|length %}, {% endif %}
{% endfor -%}
) AS trackNow if we compile the model we can see a nice set of SQL:
LIST_CONCAT(
F1 ,
F2 ,
[…]
F12 ,
F13
) AS trackWe’re getting there, but still no dice when we run the model:
$ dbt run --select stg_scans
16:54:13 Running with dbt=1.1.1
16:54:14 Found 2 models, 0 tests, 0 snapshots, 0 analyses, 167 macros, 0 operations, 2 seed files, 0 sources, 0 exposures, 0
metrics
16:54:14
16:54:14 Concurrency: 1 threads (target='dev')
16:54:14
16:54:14 1 of 1 START view model main.stg_scans ......................................... [RUN]
16:54:14 1 of 1 ERROR creating view model main.stg_scans ................................ [ERROR in 0.05s]
16:54:14
16:54:14 Finished running 1 view model in 0.21s.
16:54:14
16:54:14 Completed with 1 error and 0 warnings:
16:54:14
16:54:14 Runtime Error in model stg_scans (models/staging/stg_scans.sql)
16:54:14 Binder Error: No function matches the given name and argument types 'list_concat(VARCHAR[], VARCHAR[], VARCHAR[],
VARCHAR[], VARCHAR[], VARCHAR[], VARCHAR[], VARCHAR[], VARCHAR[], VARCHAR[], VARCHAR[], VARCHAR[], VARCHAR[])'. You might ne
ed to add explicit type casts.
16:54:14 Candidate functions:
16:54:14 list_concat(ANY[], ANY[]) -> ANY[]
16:54:14
16:54:14
16:54:14 Done. PASS=0 WARN=0 ERROR=1 SKIP=0 TOTAL=1Turns out I mis-read the docs for LIST_CONCAT — it concatenates two lists, not many. We can see this if I expand my test case from above:
current_dbt.duckdb> WITH X AS (SELECT A, B,
CASE WHEN A='X' THEN ['A'] END AS F0,
CASE WHEN B='X' THEN ['B'] END AS F1, CASE WHEN B='X' THEN ['B'] END AS F2
FROM FOO)
SELECT LIST_CONCAT(F0, F1, F2) AS COMBINED_FLAGS FROM X
Binder Error: No function matches the given name and argument types 'list_concat(VARCHAR[], VARCHAR[], VARCHAR[])'. You might need to add explicit type casts.
Candidate functions:
list_concat(ANY[], ANY[]) -> ANY[]
LINE 5: SELECT LIST_CONCAT(F0, F1, F2) AS COMBINED_FLAGS FROM X...
^The solution is to stack the LIST_CONCAT statements, as demonstrated here:
current_dbt.duckdb> WITH X AS (SELECT A, B,
CASE WHEN A='X' THEN ['A'] END AS F0,
CASE WHEN B='X' THEN ['B'] END AS F1,
CASE WHEN B='X' THEN ['B'] END AS F2
FROM FOO)
SELECT LIST_CONCAT(LIST_CONCAT(F0, F1), F2) AS COMBINED_FLAGS FROM X
+-----------------+
| COMBINED_FLAGS |
+-----------------+
| ['B', 'B'] |
| ['A'] |
| ['A', 'B', 'B'] |
+-----------------+
3 rows in set
Time: 0.009sAfter a bit of fiddling here’s the bit of the dbt model code to generate this necessary SQL:
[…]
SELECT […],
-- LIST_CONCAT takes two parameters, so we're going to stack them.
-- Write a nested LIST_CONCAT for all but one occurance of the tracks
{% for x in range((tracks|length -1)) -%}
LIST_CONCAT(
{% endfor -%}
-- For every track…
{% for t in tracks -%}
-- Write out the field number
F{{ loop.index }}
-- Unless it's the first one, add a close parenthesis
{% if loop.index !=1 %}) {% endif %}
-- Unless it's the last one, add a comma
{% if loop.index < tracks|length %}, {% endif %}
{% endfor -%}
AS track
FROM source_dataWhich compiles into this monstrosity (minus the whitespaces and verbose comments):
SELECT […]
LIST_CONCAT ( LIST_CONCAT ( LIST_CONCAT ( LIST_CONCAT ( LIST_CONCAT ( LIST_CONCAT ( LIST_CONCAT ( LIST_CONCAT ( LIST_CONCAT ( LIST_CONCAT ( LIST_CONCAT ( LIST_CONCAT (
F1 , F2 ) , F3 ) , F4 ) , F5 ) , F6 ) , F7 ) , F8 ) , F9 ) , F10 ) , F11 ) , F12 ) , F13 )
AS track
FROM source_dataThe resulting transformed data looks like this - exactly what we wanted, with a single field and zero or more instances of the Track value:
+-------------------------------------------------------+
| track |
+-------------------------------------------------------+
| ['Kafka Summit', 'Modern Data Flow'] |
| ['Panel'] |
| <null> |
| ['Kafka Summit', 'Streaming Technologies'] |
| ['Event Streaming in Academia and Beyond'] |
[…]Over on the friendly DuckDB Discord group there were a couple of suggestions how this SQL might be written more effectively and neatly, including using list_filter() with a lambda, or using list comprehension functionality which was added recently. I didn’t try either of these yet so let me know if you have done!
The other thing to say here is that the point of the Jinja templating is to make models reusable and flexible - but arguably that soup of {{ {% ( etc above may not be as straightforward to maintain in the long run given a static data set as simply copy and pasting the SQL with the hard-coded values whilst the logic is fresh in one’s head. Right tool, right job.
Staging model #3: Session IDs #
The last thing that I want to add to both staging tables is a surrogate key to represent the unique session (#6 in the spec list above). There’s a nice doc about surrogate keys on the dbt website itself. To do this I’ll create a utility staging table to generate the IDs across both sources (stg_scans, stg_ratings), and then use this in the subsequent join that I’ll do afterwards.
The two sources of data (scans and ratings) have a different number of sessions:
current_dbt.duckdb> select count (distinct session_name) from stg_scans;
+------------------------------+
| count(DISTINCT session_name) |
+------------------------------+
| 157 |
+------------------------------+
1 row in set
Time: 0.009s
current_dbt.duckdb> select count (distinct session_name) from stg_ratings
+------------------------------+
| count(DISTINCT session_name) |
+------------------------------+
| 123 |
+------------------------------+
1 row in set
Time: 0.008sSo stg_scans has the most rows, and we can check which table(s) has unique sessions in:
current_dbt.duckdb> select session_name from stg_ratings
where session_name not in
(select session_name
from stg_scans);
0 rows in set
Time: 0.006s
current_dbt.duckdb> select session_name from stg_scans
where session_name not in
(select session_name
from stg_ratings);
117 rows in set
Time: 0.032sThis tells us that all sessions that are in stg_ratings are also in stg_scans, but stg_scans has sessions that aren’t in stg_ratings.
| I made an error in my SQL above - the narrative below is still valid, but read on afterwards for a correction. |
Let’s try out creating a surrogate key using the md5 hash function.
By creating a UNION across the two tables we should get a unique list of sessions. So long as the session has the same name, it’ll have the same md5 value, and thus the same key value. We’ll try it out first for one session that we know is on both tables:
current_dbt.duckdb> select session_name
from stg_scans
where session_name in
(select session_name
from stg_ratings)
fetch first 1 row only;
+---------------------------------+
| session_name |
+---------------------------------+
| "Why Wait?" Real-time Ingestion |
+---------------------------------+
1 row in set
Time: 0.009s
current_dbt.duckdb> SELECT 'stg_ratings' AS source,
MD5(session_name) AS session_id,
session_name
FROM stg_ratings
WHERE session_name = '"Why Wait?" Real-time Ingestion'
UNION
SELECT 'stg_scans' AS source,
MD5(session_name) AS session_id,
session_name
FROM stg_scans
WHERE session_name = '"Why Wait?" Real-time Ingestion';
+-------------+----------------------------------+---------------------------------+
| source | session_id | session_name |
+-------------+----------------------------------+---------------------------------+
| stg_ratings | 43f10e52cd2f23100571189beee23450 | "Why Wait?" Real-time Ingestion |
| stg_scans | 43f10e52cd2f23100571189beee23450 | "Why Wait?" Real-time Ingestion |
+-------------+----------------------------------+---------------------------------+
2 rows in set
Time: 0.011sNote I’ve created a field called source just to show which table the value is coming from. If I remove that then the UNION de-duplicates the remaining content to give us just the one value:
current_dbt.duckdb> SELECT MD5(session_name) AS session_id,
session_name
FROM stg_ratings
WHERE session_name = '"Why Wait?" Real-time Ingestion'
UNION
SELECT MD5(session_name) AS session_id,
session_name
FROM stg_scans
WHERE session_name = '"Why Wait?" Real-time Ingestion';
+----------------------------------+---------------------------------+
| session_id | session_name |
+----------------------------------+---------------------------------+
| 43f10e52cd2f23100571189beee23450 | "Why Wait?" Real-time Ingestion |
+----------------------------------+---------------------------------+
1 row in set
Time: 0.010sLet’s check that it works where a session is only in one source table and not the other:
current_dbt.duckdb> select session_name
from stg_scans
where session_name not in
(select session_name
from stg_ratings)
fetch first 1 row only;
+----------------------------------------------------------------------------------+
| session_name |
+----------------------------------------------------------------------------------+
| A Systematic Literature Review and Meta-Analysis of Event Streaming in Academia |
+----------------------------------------------------------------------------------+
1 row in set
Time: 0.009s
current_dbt.duckdb> SELECT 'stg_ratings' AS source,
MD5(session_name) AS session_id,
session_name
FROM stg_ratings
WHERE session_name = 'A Systematic Literature Review and Meta-Analysis of Event Streaming in Academia'
UNION
SELECT 'stg_scans' AS source,
MD5(session_name) AS session_id,
session_name
FROM stg_scans
WHERE session_name = 'A Systematic Literature Review and Meta-Analysis of Event Streaming in Academia';
+-------------+----------------------------------+---------------------------------------------------------------------------------+
| source | session_id | session_name |
+-------------+----------------------------------+---------------------------------------------------------------------------------+
| stg_ratings | a8b8ea81d950cee37061756ddebc67a0 | A Systematic Literature Review and Meta-Analysis of Event Streaming in Academia |
+-------------+----------------------------------+---------------------------------------------------------------------------------+
1 row in set
Time: 0.012sCombining the two test session names gives us this:
current_dbt.duckdb> SELECT MD5(session_name) AS session_id,
session_name
FROM stg_ratings
WHERE session_name IN ('"Why Wait?" Real-time Ingestion', 'A Systematic Literature Review and Meta-Analysis of Event Streaming in Academia')
UNION
SELECT MD5(session_name) AS session_id,
session_name
FROM stg_scans
WHERE session_name IN ('"Why Wait?" Real-time Ingestion', 'A Systematic Literature Review and Meta-Analysis of Event Streaming in Academia')
+----------------------------------+---------------------------------------------------------------------------------+
| session_id | session_name |
+----------------------------------+---------------------------------------------------------------------------------+
| 43f10e52cd2f23100571189beee23450 | "Why Wait?" Real-time Ingestion |
| a8b8ea81d950cee37061756ddebc67a0 | A Systematic Literature Review and Meta-Analysis of Event Streaming in Academia |
+----------------------------------+---------------------------------------------------------------------------------+
2 rows in set
Time: 0.012sLet’s build that into a model called stg_sessionid in dbt. This will be the driving model for the joins we’ll be doing afterwards. The data above shows that in this case we could use stg_scans (because it has all of the sessions) but I’d rather do it properly and cater for the chance we have unique sessions on either side of the join.
WITH source_data AS (
-- Spec #6: Create a unique ID for each session
SELECT md5(session_name) AS session_id,
session_name
FROM {{ ref('stg_ratings') }}
UNION
SELECT md5(session_name) AS session_id,
session_name
FROM {{ ref('stg_scans') }}
)
SELECT *
FROM source_dataWhen I do dbt run now you’ll notice that it knows automagically to build stg_ratings and stg_scans before stg_sessionid because the latter depends on the first two.
$ dbt run
08:32:55 Running with dbt=1.1.1
08:32:55 Found 3 models, 0 tests, 0 snapshots, 0 analyses, 167 macros, 0 operations, 2 seed files, 0 sources, 0 exposures, 0 metrics
08:32:55
08:32:55 Concurrency: 1 threads (target='dev')
08:32:55
08:32:55 1 of 3 START view model main.stg_ratings ....................................... [RUN]
08:32:55 1 of 3 OK created view model main.stg_ratings .................................. [OK in 0.07s]
08:32:55 2 of 3 START view model main.stg_scans ......................................... [RUN]
08:32:55 2 of 3 OK created view model main.stg_scans .................................... [OK in 0.04s]
08:32:55 3 of 3 START view model main.stg_sessionid ..................................... [RUN]
08:32:55 3 of 3 OK created view model main.stg_sessionid ................................ [OK in 0.07s]
08:32:55
08:32:55 Finished running 3 view models in 0.30s.
08:32:55
08:32:55 Completed successfully
08:32:55
08:32:55 Done. PASS=3 WARN=0 ERROR=0 SKIP=0 TOTAL=3BUT… what’s this? Our shiny new table (well, technically it’s a view) shows a number I’m not expecting. Instead of 157 (the number of unique sessions in stg_ratings seen above), it’s 241.
current_dbt.duckdb> select count(*) from stg_sessionid;
+--------------+
| count_star() |
+--------------+
| 241 |
+--------------+
1 row in set
Time: 0.009sA debugging tangent #
If you’re just here for the tl;dr, or you’ve already spotted the error in my SQL above then feel free to skip ahead. But there’s something up with the SQL I’ve written and here I’m going to work it through to see what.
Problem statement: two sets of data that I believe should have a combined unique count of 157 are resulting in a view that returns a unique count of 241.
Here is the unique count of data for the two data sets:
current_dbt.duckdb> select 'stg_scans' as source_table, count(distinct session_name) from stg_scans
union select 'stg_ratings' as source_table, count(distinct session_name) from stg_ratings ;
+--------------+------------------------------+
| source_table | count(DISTINCT session_name) |
+--------------+------------------------------+
| stg_scans | 157 |
| stg_ratings | 123 |
+--------------+------------------------------+
2 rows in set
Time: 0.011sOf the 157 unique session_name values in stg_scans, 117 are not in stg_ratings whilst 40 are:
current_dbt.duckdb> select count(distinct session_name) from stg_scans
where session_name not in
(select session_name
from stg_ratings)
+------------------------------+
| count(DISTINCT session_name) |
+------------------------------+
| 117 |
+------------------------------+
1 row in set
Time: 0.011s
current_dbt.duckdb> select count(distinct session_name) from stg_scans
where session_name in
(select session_name
from stg_ratings)
+------------------------------+
| count(DISTINCT session_name) |
+------------------------------+
| 40 |
+------------------------------+
1 row in set
Time: 0.010sIn reverse, of the the 123 unique session_name values in stg_ratings, 40 are also in stg_scans (which matches the above), and 0 aren’t… this is getting a bit weird
current_dbt.duckdb> select count(distinct session_name) from stg_ratings
where session_name in
(select session_name
from stg_scans)
+------------------------------+
| count(DISTINCT session_name) |
+------------------------------+
| 40 |
+------------------------------+
1 row in set
Time: 0.010s
current_dbt.duckdb> select count(distinct session_name) from stg_ratings
where session_name not in
(select session_name
from stg_scans)
+------------------------------+
| count(DISTINCT session_name) |
+------------------------------+
| 0 |
+------------------------------+
1 row in set
Time: 0.009sSurely if there are zero in stg_ratings that are not in stg_scans then by definition they should all be in stg_scans (rather than just 40 or the 123 unique values).
Let’s look at this logically. We’re talking about a Venn diagram in which two sets overlap partially. We can export the data:
$ duckdb current_dbt.duckdb -noheader -list -c 'select distinct session_name from stg_scans order by 1' > /tmp/scans.txt
$ duckdb current_dbt.duckdb -noheader -list -c 'select distinct session_name from stg_ratings order by 1' > /tmp/ratings.txtand then drop the two resulting text files into a neat tool that I found to visualise the unique session names and the relationship between the two sets:
The tool usefully shows the resulting sets, and the four stg_ratings sessions shown are:
Apache Kafka with Spark Structured Streaming and Beyond: Building Real-Time Data Processing and Analytics with Databricks
Data Streaming Celebration
Intersectional Happy Hour
Unofficial 5K Fun RunSo let’s see if we can track those down, taking just one as an example. It’s definitely in stg_ratings:
current_dbt.duckdb> select distinct session_name from stg_ratings
where session_name = 'Unofficial 5K Fun Run';
+-----------------------+
| session_name |
+-----------------------+
| Unofficial 5K Fun Run |
+-----------------------+
1 row in set
Time: 0.007sAnd it’s definitely not in stg_scans:
current_dbt.duckdb> select distinct session_name from stg_scans
where session_name = 'Unofficial 5K Fun Run';
0 rows in set
Time: 0.001sSo what’s up with my subselect and not in logic that means it’s not being returned?
👉️ 🤦♂️ It turns out my SQL-foo is a tad rusty.
The subquery documentation on DuckDB is nice and clearly written - what I need is a correlated subquery
current_dbt.duckdb> select distinct session_name from stg_ratings r
where session_name = 'Unofficial 5K Fun Run'
and session_name not in
(select s.session_name
from stg_scans s
where s.session_name=r.session_name);
+-----------------------+
| session_name |
+-----------------------+
| Unofficial 5K Fun Run |
+-----------------------+
1 row in set
Time: 0.010sLet’s test it a step further. Based on the above tool (since I don’t trust my SQL logic, clearly for good reasons) I’ve got three sessions that I’ll use for testing:
-
Only in
stg_scans:Data Streaming: The Paths Taken -
In both:
Advancing Apache NiFi Framework Security -
Only in
stg_ratings:Unofficial 5K Fun Run
So with those in the query amended to use a correlated subquery gives us this view of sessions that are only in stg_ratings:
current_dbt.duckdb> select distinct session_name from stg_ratings r
where session_name in ( 'Data Streaming: The Paths Taken',
'Advancing Apache NiFi Framework Security',
'Unofficial 5K Fun Run' )
and session_name not in
(select s.session_name
from stg_scans s where s.session_name=r.session_name);
+------------------------------------------+
| session_name |
+------------------------------------------+
| Advancing Apache NiFi Framework Security |
| Unofficial 5K Fun Run |
+------------------------------------------+
2 rows in set
Time: 0.010s
current_dbt.duckdb>…which is not what we expected. The Advancing Apache NiFi Framework Security session is supposedly in both tables. Let’s check:
current_dbt.duckdb> select distinct session_name from stg_ratings
where session_name = 'Advancing Apache NiFi Framework Security';
+------------------------------------------+
| session_name |
+------------------------------------------+
| Advancing Apache NiFi Framework Security |
+------------------------------------------+
1 row in set
Time: 0.007s
current_dbt.duckdb> select distinct session_name from stg_scans
where session_name = 'Advancing Apache NiFi Framework Security';
0 rows in set
Time: 0.001sHmmm 🤔🤔🤔🤔
What about this:
current_dbt.duckdb> select distinct session_name from stg_scans
where session_name like '%NiFi%';
+-------------------------------------------+
| session_name |
+-------------------------------------------+
| Advancing Apache NiFi Framework Security |
+-------------------------------------------+
1 row in set
Time: 0.007s💡Ahhhh (or should that be "arrgghhh"?) Either way - we have a bit of progress. If you look closely you can see that there’s an errant whitespace (or at least unprintable character) at the end of the session name.
Let’s try it like this:
current_dbt.duckdb> select distinct session_name from stg_scans
where trim(session_name) = 'Advancing Apache NiFi Framework Security';
+-------------------------------------------+
| session_name |
+-------------------------------------------+
| Advancing Apache NiFi Framework Security |
+-------------------------------------------+
1 row in set
Time: 0.008sOK, so trim helps here. Applying this to the above query gives us this:
current_dbt.duckdb> select distinct session_name from stg_ratings r
where session_name in ( 'Data Streaming: The Paths Taken',
'Advancing Apache NiFi Framework Security',
'Unofficial 5K Fun Run' )
and trim(session_name) not in
(select trim(s.session_name)
from stg_scans s where trim(s.session_name)=trim(r.session_name));
+-----------------------+
| session_name |
+-----------------------+
| Unofficial 5K Fun Run |
+-----------------------+
1 row in set
Time: 0.013sAlrighty then! This is what we expected for these three test values.
Instead of jamming trim throughout our queries, let’s clean the data further up the pipeline, and amend the two staging models upstream to include it once. Here’s where you start to really appreciate the elegance of dbt. By defining models once it’s easy to put the logic in the right place instead of bodging it in subsequent queries.
$ git diff models/staging/stg_ratings.sql
[…]
- SELECT title AS session_name,
+ SELECT TRIM(title) AS session_name,
$ git diff models/staging/stg_scans.sql
[…]
- SELECT NAME AS session_name,
+ SELECT TRIM(name) AS session_name,After making that change we do a dbt run and re-run the test query above to see how things look now. I’m going to add three more test session values too, one for each category (in one, in the other, in both)
current_dbt.duckdb> -- Two sessions only in stg_ratings
select distinct session_name from stg_ratings r
where session_name in ( 'Data Streaming: The Paths Taken', 'Streaming Use Cases and Trends',
'Advancing Apache NiFi Framework Security', 'Bootiful Kafka: Get the Message!',
'Unofficial 5K Fun Run', 'Data Streaming Celebration' )
-- only in the first set
-- 👇️ 👇️
and session_name not in (select s.session_name from stg_scans s where s.session_name=r.session_name);
+----------------------------+
| session_name |
+----------------------------+
| Data Streaming Celebration |
| Unofficial 5K Fun Run |
+----------------------------+
2 rows in set
Time: 0.009s
current_dbt.duckdb> -- Two sessions in both stg_ratings and stg_scans
select distinct session_name from stg_ratings r
where session_name in ( 'Data Streaming: The Paths Taken', 'Streaming Use Cases and Trends',
'Advancing Apache NiFi Framework Security', 'Bootiful Kafka: Get the Message!',
'Unofficial 5K Fun Run', 'Data Streaming Celebration' )
-- in both sets 👇️
and session_name in (select s.session_name from stg_scans s where s.session_name=r.session_name);
+------------------------------------------+
| session_name |
+------------------------------------------+
| Advancing Apache NiFi Framework Security |
| Bootiful Kafka: Get the Message! |
+------------------------------------------+
2 rows in set
Time: 0.009s
current_dbt.duckdb> -- Two sessions in only stg_scans
select distinct session_name from stg_scans s
where session_name in ( 'Data Streaming: The Paths Taken', 'Streaming Use Cases and Trends',
'Advancing Apache NiFi Framework Security', 'Bootiful Kafka: Get the Message!',
'Unofficial 5K Fun Run', 'Data Streaming Celebration' )
-- only in the first set
-- 👇️ 👇️
and session_name not in (select r.session_name from stg_ratings r where r.session_name=s.session_name);
+---------------------------------+
| session_name |
+---------------------------------+
| Data Streaming: The Paths Taken |
| Streaming Use Cases and Trends |
+---------------------------------+
2 rows in set
Time: 0.015sOK, we’re looking good. Let’s try it without the predicates. There should be four rows returned for sessions only in stg_ratings:
current_dbt.duckdb> select distinct session_name from stg_ratings r
-- only in the first set
-- 👇️ 👇️
where session_name not in (select s.session_name from stg_scans s where s.session_name=r.session_name);
+---------------------------------------------------------------------------------------------------------------------------+
| session_name |
+---------------------------------------------------------------------------------------------------------------------------+
| Apache Kafka with Spark Structured Streaming and Beyond: Building Real-Time Data Processing and Analytics with Databricks |
| Data Streaming Celebration |
| Unofficial 5K Fun Run |
| Intersectional Happy Hour |
+---------------------------------------------------------------------------------------------------------------------------+
4 rows in set
Time: 0.013s💥💥💥💥
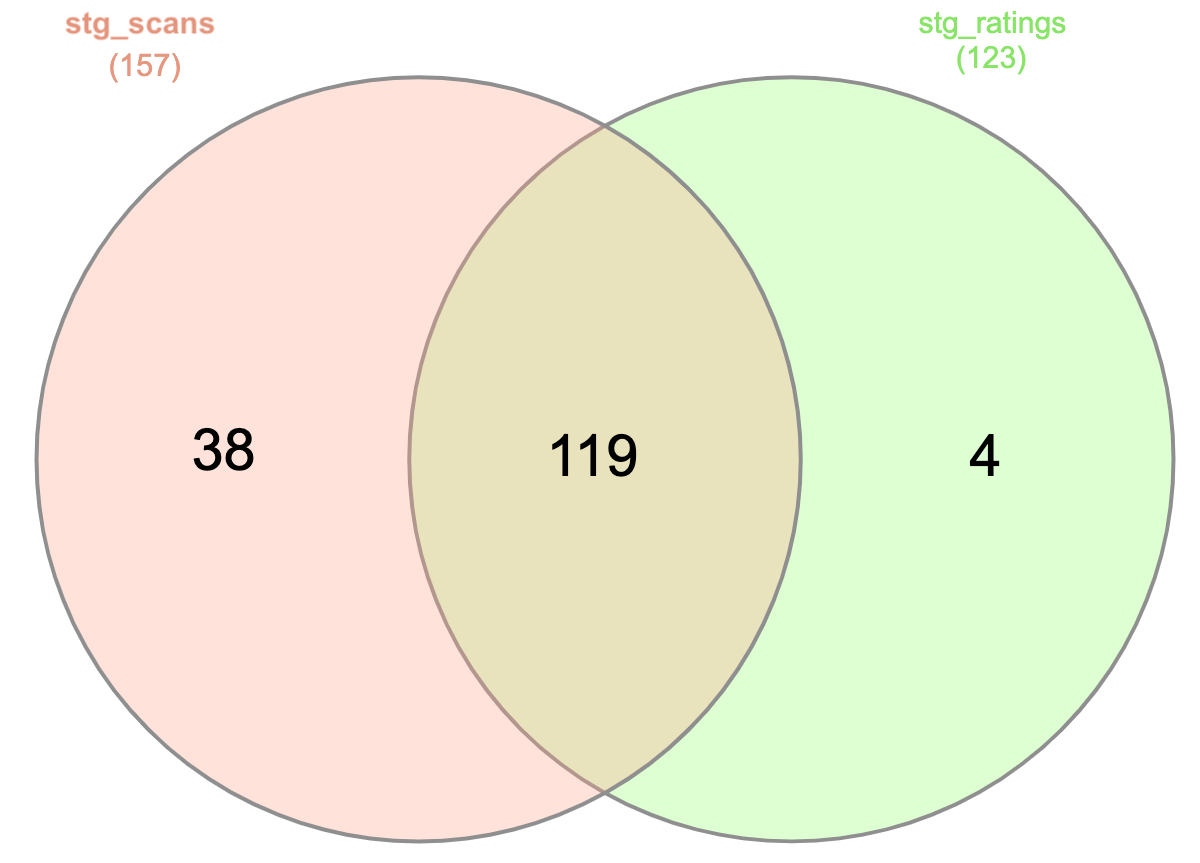
Remember that Venn diagram above? This one:
Let’s check those numbers against our newly-fixed SQL and data:
current_dbt.duckdb> -- In ONLY stg_scans
select COUNT(distinct session_name) from stg_scans s
-- only in the first set
-- 👇️ 👇️
where session_name not in (select r.session_name from stg_ratings r where r.session_name=s.session_name);
+------------------------------+
| count(DISTINCT session_name) |
+------------------------------+
| 38 |
+------------------------------+
1 row in set
Time: 0.012s
current_dbt.duckdb> -- In BOTH stg_ratings and stg_scans
select COUNT(distinct session_name) from stg_ratings r
-- in BOTH sets
-- 👇️
where session_name in (select s.session_name from stg_scans s where s.session_name=r.session_name);
+------------------------------+
| count(DISTINCT session_name) |
+------------------------------+
| 119 |
+------------------------------+
1 row in set
Time: 0.014s
current_dbt.duckdb> -- In ONLY stg_ratings
select COUNT(distinct session_name) from stg_ratings r
-- only in the first set
-- 👇️ 👇️
where session_name not in (select s.session_name from stg_scans s where s.session_name=r.session_name);
+------------------------------+
| count(DISTINCT session_name) |
+------------------------------+
| 4 |
+------------------------------+
1 row in set
Time: 0.012sNormal service has been resumed… #
If you stayed with me on that tangent… bravo. If you didn’t, that’s understandable. It’s like being at a conference where the speaker doing a demo "Um"s an "Ah"s and "It was working when I tried it before" through an error and everyone else gets restless and goes to check Twitter.
So I made a mistake in my initial analysis and numbers. Instead of 157 unique sessions there should be 38 + 119 + 4 = 161. Let’s see what the fix we put in for whitespace (trim) has done to the results of stg_sessionid:
current_dbt.duckdb> select count(*) from stg_sessionid;
+--------------+
| count_star() |
+--------------+
| 162 |
+--------------+
1 row in set
Time: 0.012s162! It’s almost 161! But not quite!
How about this, on a hunch:
current_dbt.duckdb> select count(*) from stg_sessionid where session_name is not null;
+--------------+
| count_star() |
+--------------+
| 161 |
+--------------+
1 row in set
Time: 0.013sThere we have it ladies and gentlemen! The number that we were (eventually) expecting. Let’s check the data first to make sure we’ve not got a data issue that we need to fix upstream (i.e. valid data but no session name):
current_dbt.duckdb> select * from stg_scans where session_name is null;
+--------------+----------+--------+-----------+--------+
| session_name | speakers | scans | rating_ct | track |
+--------------+----------+--------+-----------+--------+
| <null> | <null> | <null> | <null> | <null> |
| <null> | <null> | <null> | <null> | <null> |
+--------------+----------+--------+-----------+--------+
2 rows in set
Time: 0.012sThat looks good to remove, so we’ll tweak the stg_sessionid model to exclude NULL sessions:
diff --git a/current_dbt/models/staging/stg_sessionid.sql b/current_dbt/models/staging/stg_sessionid.sql
index 1eb3743..5fbe8de 100644
--- a/current_dbt/models/staging/stg_sessionid.sql
+++ b/current_dbt/models/staging/stg_sessionid.sql
@@ -11,3 +11,4 @@ WITH source_data AS (
SELECT *
FROM source_data
+WHERE session_name IS NOT NULLAfter re-running all the models, the stg_sessionid is showing exactly the right count:
current_dbt.duckdb> select count(*) from stg_sessionid;
+--------------+
| count_star() |
+--------------+
| 161 |
+--------------+
1 row in set
Time: 0.013sStaging model 3.5 - Sessions #
It’s probably going to be more useful to have a unique list of sessions and their associated attributes (speaker, etc), so I’m going to amend the stg_sessionid to be stg_session and add these in. There are couple of factual attributes (number of scans, number of ratings) which are arguably facts, but I’ll worry about that another day. For now it’s all at the same grain (session) and so makes sense in the same place:
WITH source_data AS (
-- Spec #6: Create a unique ID for each session
SELECT md5(session_name) AS session_id,
session_name
FROM {{ ref('stg_ratings') }}
UNION
SELECT md5(session_name) AS session_id,
session_name
FROM {{ ref('stg_scans') }}
)
SELECT src.session_id,
src.session_name,
sc.speakers,
sc.track,
SUM(sc.scans) AS scans,
SUM(sc.rating_ct) AS rating_ct
FROM src.source_data src
LEFT OUTER JOIN
{{ ref('stg_scans') }} sc
ON src.session_name = sc.session_name
WHERE src.session_name IS NOT NULL
GROUP BY src.session_id,
src.session_name,
sc.speakers,
sc.trackYou’ll notice a SUM and GROUP BY in there, because some sessions had multiple scan and rating data which needed rolling up. This also highlighted a type error in the stg_scans which I went back and fixed in the model (instead of just kludging it in-place here):
diff --git a/current_dbt/models/staging/stg_scans.sql b/current_dbt/models/staging/stg_scans.sql
[…]
- scans AS scans,
+ TRY_CAST(scans AS INT) AS scans,The finished result - Model 1: Session Rating Detail #
For this, we’ll just instantiate the session rating detail that we just built in staging, joined with the session dimension data:
SELECT s.session_id,
s.session_name,
s.speakers,
r.virtual_attendee,
r.overall_experience_rating,
r.presenter_rating,
r.content_rating,
r.overall_experience_comment,
r.presenter_comment,
r.content_comment
FROM {{ ref('stg_ratings')}} r
LEFT JOIN
{{ ref('stg_session') }} s
ON s.session_name = r.session_nameWhen we run the whole project we can see again that dbt just figures out the dependencies so that everything’s built in the right order:
$ dbt run
11:43:23 Running with dbt=1.1.1
11:43:23 Found 4 models, 0 tests, 0 snapshots, 0 analyses, 167 macros, 0 operations, 2 seed files, 0 sources, 0 exposures, 0 metrics
11:43:23
11:43:23 Concurrency: 1 threads (target='dev')
11:43:23
11:43:23 1 of 4 START view model main.stg_ratings ....................................... [RUN]
11:43:23 1 of 4 OK created view model main.stg_ratings .................................. [OK in 0.07s]
11:43:23 2 of 4 START view model main.stg_scans ......................................... [RUN]
11:43:23 2 of 4 OK created view model main.stg_scans .................................... [OK in 0.07s]
11:43:23 3 of 4 START view model main.stg_session ....................................... [RUN]
11:43:23 3 of 4 OK created view model main.stg_session .................................. [OK in 0.04s]
11:43:23 4 of 4 START table model main.session_ratings_detail ........................... [RUN]
11:43:23 4 of 4 OK created table model main.session_ratings_detail ...................... [OK in 0.08s]
11:43:23
11:43:23 Finished running 3 view models, 1 table model in 0.41s.
11:43:23
11:43:23 Completed successfully
11:43:23
11:43:23 Done. PASS=4 WARN=0 ERROR=0 SKIP=0 TOTAL=4Over in DuckDB we can see our seed data, three staging views, and a table…
$ duckdb current_dbt.duckdb -c "select table_schema, table_name, table_type from information_schema.tables;"
┌────────────────┬────────────────────────┬────────────┐
│ table_schema │ table_name │ table_type │
├────────────────┼────────────────────────┼────────────┤
│ main_seed_data │ session_scans │ BASE TABLE │
│ main_seed_data │ rating_detail │ BASE TABLE │
│ main │ stg_session │ VIEW │
│ main │ stg_ratings │ VIEW │
│ main │ stg_scans │ VIEW │
│ main │ session_ratings_detail │ VIEW │
└────────────────┴────────────────────────┴────────────┘Except - our finished table (session_ratings_detail) is still a VIEW. Over in dbt_project.yml I need to tell dbt to actually materialise it:
[…]
models:
current_dbt:
materialized: table
staging:
+materialized: viewWhich has the desired effect:
$ duckdb current_dbt.duckdb -c "select table_schema, table_name, table_type from information_schema.tables;"
┌────────────────┬────────────────────────┬────────────┐
│ table_schema │ table_name │ table_type │
├────────────────┼────────────────────────┼────────────┤
│ main_seed_data │ session_scans │ BASE TABLE │
│ main_seed_data │ rating_detail │ BASE TABLE │
│ main │ session_ratings_detail │ BASE TABLE │
│ main │ stg_session │ VIEW │
│ main │ stg_ratings │ VIEW │
│ main │ stg_scans │ VIEW │
└────────────────┴────────────────────────┴────────────┘And a sample of the finished data:
current_dbt.duckdb> select session_id, overall_experience_comment, presenter_rating, content_rating from session_ratings_detail;
+----------------------------------+----------------------------+------------------+----------------+
| session_id | overall_experience_comment | presenter_rating | content_rating |
+----------------------------------+----------------------------+------------------+----------------+
| 2487f06e9800cbe86e35df66d8df2e27 | I want more Flink! | <null> | <null> |
| 2487f06e9800cbe86e35df66d8df2e27 | <null> | 4 | <null> |
| 2487f06e9800cbe86e35df66d8df2e27 | <null> | <null> | 4 |
| 2487f06e9800cbe86e35df66d8df2e27 | <null> | 5 | <null> |
| 2487f06e9800cbe86e35df66d8df2e27 | <null> | <null> | 5 |The finished result - Model 2: Session Summary #
The breakdown of individual ratings data as we just created is useful for deep-dive analysis, but what’s going to be useful overall is a summary of each session’s data, which is what we’ll create with the sessions.sql model. Check out the explanation below for notes.
{% set rating_areas = ['overall_experience','presenter', 'content'] %}
{% set rating_types = ['rating','comment'] %}
WITH ratings_agg AS (
SELECT session_id,
{% for a in rating_areas -%}
{% for r in rating_types -%}
LIST_SORT(
LIST({{a}}_{{r}}),
'DESC') AS {{a}}_{{r}},
{% endfor -%}
{% endfor -%}
FROM {{ ref('session_ratings_detail')}}
GROUP BY session_id
)
SELECT s.session_id,
s.session_name,
s.speakers,
s.track,
s.scans,
{% for a in rating_areas -%}
LIST_FILTER({{a}}_rating,x->x IS NOT NULL) AS {{a}}_rating_detail,
LIST_MEDIAN({{a}}_rating) AS {{a}}_rating_median,
LIST_FILTER({{a}}_comment,x->x IS NOT NULL) AS {{a}}_comments,
{% endfor -%}
s.rating_ct
FROM {{ ref('stg_session')}} s
LEFT JOIN
ratings_agg r
ON s.session_id = r.session_idThe main point of interest in the model here is compressing the above session_ratings_detail using the LIST data type and subsequent filter, aggregate, and sort functions.
-
Build a
LISTas an aggregate:SELECT LIST(content_rating) FROM session_ratings_detail GROUP BY session_id;Note that the
LISTgets an entry even if there’s no value:+----------------------------------------------------------+ | list(content_rating) | +----------------------------------------------------------+ |[None, None, 4, None, None, None, None, 5, None, None, 3] | -
Sort the list with
LIST_SORT:SELECT LIST_SORT(LIST(content_rating),'DESC') FROM session_ratings_detail GROUP BY session_id;+-----------------------------------------------------------+ | list_sort(list(content_rating), 'DESC') | +-----------------------------------------------------------+ | [None, None, None, None, None, None, None, None, 5, 4, 3] | +-----------------------------------------------------------+ -
Filter the list using
LIST_FILTERand a LambdaWITH agg AS (SELECT session_id, LIST_SORT(LIST(content_rating),'DESC') as my_list FROM session_ratings_detail GROUP BY session_id) SELECT LIST_FILTER(my_list, returned_field -> returned_field IS NOT NULL) FROM agg;+----------------------------------------------------------------------+ | list_filter(my_list, returned_field -> (returned_field IS NOT NULL)) | +----------------------------------------------------------------------+ | [5, 4, 3] | -
Aggregate the contents of the list using
LIST_AGGREGATEwhich provides a list of rewrites - you’ll see in the following example both return the same result:WITH agg AS (SELECT session_id, LIST_SORT(LIST(content_rating),'DESC') as my_list FROM session_ratings_detail GROUP BY session_id) SELECT my_list, LIST_AGGREGATE(my_list, 'median'), LIST_MEDIAN(my_list) FROM agg;The resulting data looks like this:
+-----------------------------------------------------------+-----------------------------------+----------------------+ | my_list | list_aggregate(my_list, 'median') | list_median(my_list) | +-----------------------------------------------------------+-----------------------------------+----------------------+ | [None, None, None, None, None, None, None, None, 5, 4, 3] | 4.0 | 4.0 |
The resulting sessions table looks like this:
current_dbt.duckdb> select *
from sessions
+----------------------------------+---------------------------------------+-------------+-------------------------------------------------+-------+----------------------------------+----------------------------------+-----------------------------------------------------------------+--------------------------+-------------------------+----------------------+--------------------------+-----------------------+------------------+-----------+
| session_id | session_name | speakers | track | scans | overall_experience_rating_detail | overall_experience_rating_median | overall_experience_comments | presenter_rating_detail | presenter_rating_median | presenter_comments | content_rating_detail | content_rating_median | content_comments | rating_ct |
+----------------------------------+---------------------------------------+-------------+-------------------------------------------------+-------+----------------------------------+----------------------------------+-----------------------------------------------------------------+--------------------------+-------------------------+----------------------+--------------------------+-----------------------+------------------+-----------+
| 4eac7c6d30952b9a20f216c897a5a5ef | Never Gonna Give you Up | Rick Astley | ['Data Development Life Cycle', 'Kafka Summit'] | 107 | [5, 5, 5, 5, 5, 4, 4, 3] | 5.0 | ['Very informative and hope to bring ideas back to my company'] | [5, 5, 5, 5, 5, 5, 5, 3] | 5.0 | ['Very well spoken'] | [5, 5, 5, 5, 5, 4, 4, 3] | 5.0 | [] | 24 |
+----------------------------------+---------------------------------------+-------------+-------------------------------------------------+-------+----------------------------------+----------------------------------+-----------------------------------------------------------------+--------------------------+-------------------------+----------------------+--------------------------+-----------------------+------------------+-----------+Wrapping up #
With the seed, staging, and main models built, I’ve got a project that transforms two raw CSV files into a nicely (-ish) modelled set of data. I’ve not touched things like incremental loads, schema.yml definitions, docs, tests, snapshots, and all the rest of it. But I have picked up an appreciation for what dbt can do, and why there is such a fuss about it.
Could I have written this all myself without dbt? Sure. Would I have wanted to? Perhaps. Would it have been so easy to easily go back and change definitions of staging tables as I realised I’d missed columns, mis-typed data, etc? Definitely not. Would it have been possible to give a list of values and iterate over them to dynamically build SQL? I guess, but coding anything other than SQL really isn’t my bag - "just enough" coding here seems the perfect amount, sticking to the declarative power of SQL for the vast bulk of transformation work.
Comments? #
This is my first proper outing with dbt, other than following along someone else’s code previously. I’d love to hear any feedback on my approach with it - what did I do wrong? What wasn’t dbtonic? What other features should I dig into? Hit me up on twitter or LinkedIn 😁
Data Engineering in 2022 #
-
Query & Transformation Engines [TODO]
